



Building a Modern Data Layer for a High-growth SaaS Company
Hedge your company's success with a data layer from Atadataco.com and avoid data chaos.

Problem Statement: Business Leaders can’t use customer data to make core business decisions.
Sketchy’s Data Problem...Situation. ⏳
Context: Sketchy.com builds training and educational products for medical school students.
Problem: Team confidence in their data infrastructure and understanding of the customer’s product was low. Marketing used one dataset. Sales used another. Product, a third.
Opportunity: Each team thought they could see the complete view of the customer. How
can you trust your data if you have three definitions for gross revenue?
Sketchy’s CPO wanted to know:
What’s the customer trying to accomplish?
How do the customers’ goals align with the company’s goals?
What customer actions drive trial account conversion?
Desired Outcome: Maturing a growing company’s data strategy and infrastructure to scale with them delivers more than building a better stack.
Sketchy Starting State.
I was brought in as an outside data architect to pick up the work from previous firms. The below system was fragmented with data quality issues from Postgres, multiple and duplicate schemas of product analytics information, and no central data model.

Insight and stakeholders...Insight. 💡
The core opportunity to unlock product growth and trust in data...Integrating these three views of data from Marketing, Finance, and Product teams:
-> Remove vendor data silos and replace them with unified data access.
-> Deliver single-source-of-truth so all business stakeholders can collaborate on customer analytics.
-> New platforms/vendors must be capable of efficient integration without requesting Eng support.
Data maturity journey.
I view building a data layer for a new client as following the maturity journey. It's not a statement of company size aligned to which stack is needed. It's a statement that you have to work through a Starter Stack before you can build a Growth Stack and so forth. My goals are to drive impact, take the time to architect a stack that will grow to meet the company's needs, and avoid data pitfalls as the models and functions become more sophisticated.

Where Sketchy wanted to be.
Project Goals = Starter Stack. 🥅
Sketchy wanted that solid foundation that would support the fast-growing company they already were. They wanted experimentation and eventually machine learning, but first they wanted a strong, stable foundation that could scale with them. Their primary tenants where
Self-service for all non-technical and business teams.
A single data modeling layer controlling all business metric definitions.
DataOps to add QA and validate data at source = BI dashboards.
Plan for hiring, reduce infrastructure costs, and formalize contract between Engineering, and Data.
My approach for Sketchy. 🛬

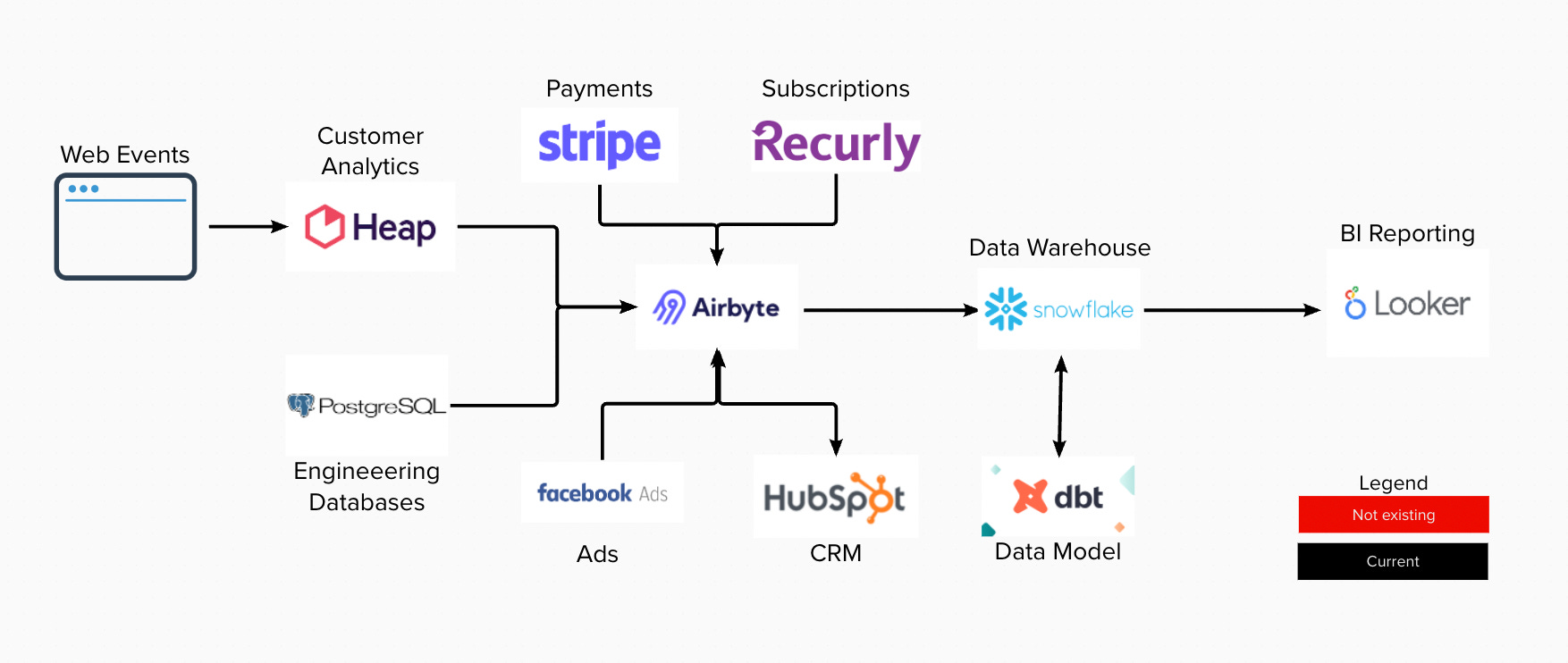
Stage one: integrating existing product/web data with ad and revenue datasets.
Stage two: building a data warehouse and metrics system for sharing customer insights.
Stage three: validating all datasets and training the team in self-service.
Stage four: evangelize best practices and define a hiring plan.
Project implementation Stages.
Stage one:
Build LookML data relationships from the base of web events.
Build from scratch data model for the product, marketing, CS, and finance teams.
Stage two:
Build a central metrics layer for the business in Looker to unify metric definitions.
Move data modeling from LookML to DBT by building defining SQL transformation layer.
Stage three:
QA and add DBT tests to every dataset.
Deliver product, marketing, and company dashboards.
Stage four:
Complete infrastructure rebuild plan.
Cost-saving initiatives.
Optimize all queries and switch to incremental builds.
Ownership strategy for infrastructure.
Move to Airbyte and Snowflake for more control of their new backend RDS infra.
One-year hiring and team development plan.
Project outcome. 🚀
Sketchy reported executives trusted their new data platform. They had cross-company, customer analytics that worked.
Self-serve analytics worked for Sketchy. Their customer insights from the platform drove a six-figure revenue lift in the first year by correctly identifying and removing account sharing.
They had...
Trust in data.
Adding custom ad hoc requests now only requires a single new dashboard or SQL file added to the data model.
Centralized reporting drives better collaboration and quicker customer insights.
Save 100K in year one from analytics insights.
Next steps with Atadataco.
Achieved: Sketchy complete analytics stack and data pipeline rebuild.
Next Steps: Sketchy opted for more control and ownership of their data stack.
The first on the roadmap was Airbyte + Snowflake to replace Fivetran + BigQuery for more flexibility and cost savings.
The second was to implement end-to-end integration testing.
The third was a formal experimentation engine to drive faster growth.
Now they had a collaborative, scalable Starter Stack. Now they could build their Growth Stack with confidence.
Trusted by high-growth companies and founders like Sketchy. 🤝
Our managed data layer and building methods work whether you are starting from scratch or growing into a bigger data stack. We scale to match your needs and your business goals. Let us collaborate with you in every stage of development.
Our specialty is the startup space. We have built complete, trusted analytics platforms for many verticals including AdTech, e-Commerce, Fashion, FinTech, MarTech, Medical, Recruiting, SAAS, Sales, and Security.
Schedule a time for us to review your business needs and recommend a managed data stack sized perfectly for your company: Atadataco.com/contact.
I picked up a project that was largely in the same state as your end state, and the additions to the above Starter Stack was:
1. Allow product team to take better control of event definitions (using Avo). I think this is probably more important than most realise, and the first thing that teams will struggle with once they get beyond accessing everything.
2. Improve the actual product analytics capabilities. Using dbt+Looker for Product analytics is in my mind an anti-pattern as it leads to a huge bottleneck for product teams to answer their own questions. We ended up using Posthog.
The Starter Stack you describe is great for pure BI tool consolidation reporting, but pure BI is pretty static and frustrating for Product teams, hence the additions. The additions create infrastructure headaches, but worthwhile for the sake of Product teams.